JavaScriptでMarkdownパーサの作成
2020/4/23 パーサを修正し生成コードが変わりました。変更内容はこちら。
JavaScriptでMarkdownのパーサを書いてみた。
Markdownはブログ記事みたいな感じの文書をお手軽に記述するための記法で、主にhtmlに変換される。github等のサービスで採用されてるためか、最近プログラマにのみ認知度が高い。
動機
イマドキは仕様書なんかもWord文書ではなくMarkdownで書いたりすることもあると聞いた。Markdownでドキュメントを書いた場合のメリットは以下のような感じか
- 手っ取り早く書ける
- テキストエディタで編集できる
- gitでバージョン管理できる
- github等のWebサービス上に載せられる
- 参照ページ等へリンクができる
逆にパッと思いつくデメリットはというと
- レイアウトに融通が利かない
- 図などをその場で編集できない
- 単一ファイルにならない(画像など)
- 印刷が前提になっていない
結構デメリットが強い。ドキュメントがすべてこれで済むのはかなり限定的かと思う。まあでも今はみんなWebの表示にも慣れてるし、マニュアルやリファレンスなんかにはいいかもしれない。
いやそれ以前に
読めないんじゃ~。mdファイルを見てVisual Studio Code(Markdownをプレビューできる)とかに突っ込んでくれるのなんてプログラマだけなんじゃ~。もしくはWebサービスに載せるの前提か。
それじゃ用途が限られすぎるので、ローカルファイルの状態でwebブラウザで開いて読めるようにパーサを作るよ。まあ世の中には既に高性能なライブラリがあるんだけど、再配布のライセンス問題回避なんかも含めて車輪の再開発だ。
ソースコード
githubに置いてあるのでそっちを見てね。
MDParser
実行結果
一個ずつ書いてくのも面倒くさいのでまとめて。
Markdown
以下のようなMarkdownを書いたとする。
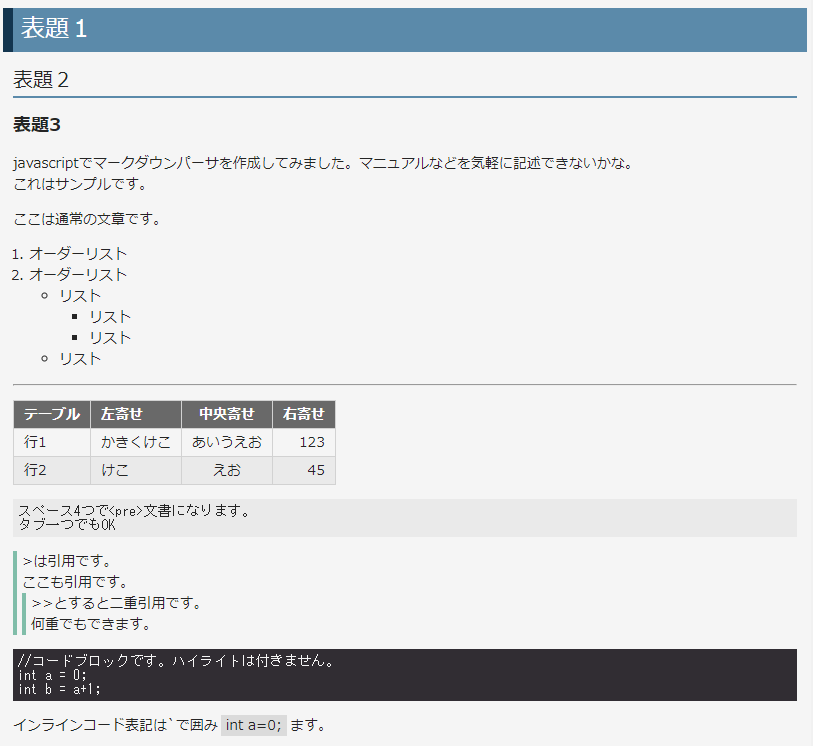
# 表題1
## 表題2
### 表題3
javascriptでマークダウンパーサを作成してみました。マニュアルなどを気軽に記述できないかな。
これはサンプルです。
ここは通常の文章です。
1. オーダーリスト
1. オーダーリスト
- リスト
- リスト
- リスト
- リスト
---
|テーブル|左寄せ|中央寄せ|右寄せ|
|---|:---|:---:|---:|
| 行1 | かきくけこ | あいうえお | 123 |
| 行2 | けこ | えお | 45 |
スペース4つで<pre>文書になります。
タブ一つでもOK
> >は引用です。
> ここも引用です。
>> >>とすると二重引用です。
>> 何重でもできます。
```c
//コードブロックです。ハイライトは付きません。
int a = 0;
int b = a+1;
```
インラインコード表記は`で囲み`int a=0;`ます。
ここは*アクセント*です。
ここは __強調__ です。
ここは***アクセント+強調***です。
*と _のどちらをも使えます。この辺のインライン要素は\*等でエスケープされます。
ここは~~取り消し~~です。
リンクです[Google](http://google.com)。別窓(_blank)になります。
画像表示です。

それを文字列として MDParser.BuildHtml() に渡してやると、戻り値で生成されたhtmlが返ってくる。
document.body.innerHTML = new MDParser().BuildHtml(markdown_str)
画面表示
こんな感じで表示される。

HTML
生成されるHTMLはこんな感じ。
<h1>表題1</h1>
<h2>表題2</h2>
<h3>表題3</h3>
<p>javascriptでマークダウンパーサを作成してみました。マニュアルなどを気軽に記述できないかな。<br />
これはサンプルです。</p>
<p>ここは通常の文章です。</p>
<ol>
<li>オーダーリスト</li>
<li>オーダーリスト
<ul>
<li>リスト
<ul>
<li>リスト</li>
<li>リスト</li>
</ul>
</li>
<li>リスト</li>
</ul>
</li>
</ol>
<hr />
<table>
<thead>
<tr>
<th style='text-align:initial;'>テーブル</th>
<th style='text-align:left;'>左寄せ</th>
<th style='text-align:center;'>中央寄せ</th>
<th style='text-align:right;'>右寄せ</th>
</tr>
</thead>
<tbody>
<tr>
<td style='text-align:initial;'>行1</td>
<td style='text-align:left;'>かきくけこ</td>
<td style='text-align:center;'>あいうえお</td>
<td style='text-align:right;'>123</td>
</tr>
<tr>
<td style='text-align:initial;'>行2</td>
<td style='text-align:left;'>けこ</td>
<td style='text-align:center;'>えお</td>
<td style='text-align:right;'>45</td>
</tr>
</tbody>
</table>
<pre>
スペース4つで<pre>文書になります。
タブ一つでもOK</pre>
<blockquote>
<span class='blockquoteNest'>>は引用です。</span><br />
<span class='blockquoteNest'>ここも引用です。</span><br />
<span class='blockquoteNest'><span class='blockquoteNest'>>>とすると二重引用です。</span></span><br />
<span class='blockquoteNest'><span class='blockquoteNest'>何重でもできます。</span></span>
</blockquote>
<pre class='codeblock code_c'>//コードブロックです。ハイライトは付きません。
int a = 0;
int b = a+1;</pre>
<p>インラインコード表記は`で囲み<span class='inlinecode'>int a=0;</span>ます。</p>
<p>ここは<em>アクセント</em>です。<br />
ここは<strong>強調</strong>です。<br />
ここは<strong><em>アクセント+強調</em></strong><em></em>です。<br />
*と _のどちらをも使えます。この辺のインライン要素は\*等でエスケープされます。</p>
<p>ここは<del>取り消し</del>です。</p>
<p>リンクです<a href='http://google.com' target='_blank'>Google</a>。別窓(_blank)になります。</p>
<p>画像表示です。<br />
<img alt='画像表示のサンプル' src='./sample/img/icon.png'></p>
ここでは整形して載せたけど実際は改行やインデントは入らない。基本的にstyleは付けないので装飾は別途スタイルシートを適用する。
特徴的な部分は、
・構文で使う記号は文字参照に変換される
・2重引用がblockquoteのネストではなく階層分spanで囲むような生成になってる
・コードのハイライト機能はない。でも[code_種別指定]というclassが付くので判別は可
・チェックボックスには非対応(用途が思いつかないので)
このくらいか。それ以外はオーソドックスなマークアップだと思う。一部CSSセレクタ用に固定のクラス名が付加されるが、これはパラメータ化できてもいいかもしれない。
所感
一般的に言語解析は 字句解析→構文解析→意味解析 と行うが、Markdownは記法に統一感が無くトークン分けできないので、単純に1行ずつ正規表現で置き換えていった。空白や構文の終了判定など、パーサによって解析に癖が出るのもわかる。
まあ明確だが煩雑なマークアップに対して、人間の書きやすさ重視ということなんだろう。名前もマークアップのもじりだし。
シンタックスハイライト機能は無いが、外部ライブラリなしで400行弱と軽量。
実用上の問題
実は解析とは関係ないところで問題が。元々ローカルファイルで扱うことを目的に作ったのに、ブラウザのローカル実行(file://~)だとセキュリティにより別ファイルに記述したテキストを取得する手段が無いことに気づいた。
一応対処方法は考えてみたので、それは次回。
コメント
コメントを投稿